
Previous article

The problem with delta loads from transactional systems

At Celonis, we use delta loads to make the data available to our customers as quickly as possible. A delta load means that we do not repeatedly extract the entire data of a table, but only the new data that has been added to a table since the last load.
To enable delta loads we need to identify in a table which rows have been extracted already and which ones are new or updated. We rely on a timestamp, such as modified date, selecting rows where the timestamp is greater than the maximum already extracted. Lately we have discovered that in certain situations this can lead to rows being left unextracted. Want to know why?
Background and testing environment
We were assessing the possibility of delta loading rows from a so-called change log table we create in SAP systems. The change log table contains a row for each change or update that occurs. The idea was simple: add a column to the change log table that contains the timestamp of the row. When extracting from the change log table, the rows where the timestamp is greater than the maximum already extracted are selected. The cached maximum timestamp is updated after each extraction.
We were testing on SAP servers that use Oracle and HANA as their databases. Their standard isolation level is committed reads (i.e. transactions are solely able to read committed changes). It’s important to note for later that neither allow dirty reads (i.e. reading of changes that have been conducted by another running transaction and not yet committed) since they are able to provide lock-free reads without the side effect of being able to read uncommitted changes from other transactions.
Discovery of possible unextracted rows
When discussing the implementation details we identified that when several database operations are wrapped in a transaction, which itself can be run concurrently with other transactions, it can lead to rows with older timestamps being committed after those with newer ones.
Please follow this chain of events (scripting in HANA) to both reproduce this and see why it is problematic for delta loads:
1. Create a table that contains three columns:
ID: auto-increment
Name: string
Timestamp: insertion timestamp.
CREATE TABLE ZTEST (
ID VARCHAR(5),
NAME VARCHAR(20),
TIMESTAMP VARCHAR(20));
2. Create a sequence to enable an auto-increment for the ID.
CREATE SEQUENCE seq
START WITH 1
INCREMENT BY 1 ;
3. Insert a value into your table to check if everything works as expected.
INSERT INTO ZTEST VALUES (
seq.NEXTVAL,
'old',
TO_CHAR(CURRENT_TIMESTAMP, 'YYYY-MM-DD HH:MI:SS'))
4. Create a procedure to mimic a batch insert.
CREATE PROCEDURE "batch_insert"() AS BEGIN
DECLARE counter INT := 0;
WHILE counter < 1000 DO
counter := counter + 1;
INSERT INTO ZTEST VALUES (
seq.NEXTVAL,
'batch-insert',
TO_CHAR(CURRENT_TIMESTAMP, 'YYYY-MM-DD HH:MI:SS'));
END WHILE;
END;
5. Call the procedure and then move quickly to step 6 as we need the two queries to run in parallel. In other databases you can use a sleep() command in the procedure to make this timing easier.
This is a fairly standard situation in databases, for example in SAP having several queries to update invoice statuses wrapped in a LUW (more information) , several copies of which could be running at once.
CALL "batch_insert"();
6. Open another session and execute a single insert while the procedure from step 5 is still running.
INSERT INTO ZTEST VALUES (
seq.NEXTVAL ,
'single-insert',
TO_CHAR(CURRENT_TIMESTAMP, 'YYYY-MM-DD HH:MI:SS'))
7. When the single insert finishes and commits and the batch insert is still running the resulting table will only have the single insert visible. The entries of the batch insert will only be visible after the complete transaction finishes and is committed.
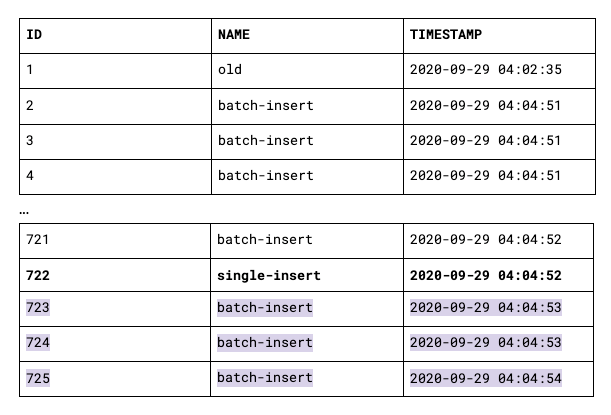
Assume we are extracting at this point in time from the table and load the latest timestamp 2020-09-29 04:04:52 into the cache.

8. When the batch insert then finishes, the resulting table will look like the one below. Clearly visible is that the database calculates the timestamp mid-transaction, not on commit.
Assume we are extracting again, filtering on “timestamp > MAX(timestamp)”, whereby the cached maximum timestamp is 2020-09-29 04:04:52. We will only extract the rows highlighted in purple. The rows with ID 2 to 721 will not be extracted because their timestamp is less than what was received in the first delta load.
Findings and solution
Delta loading based on a current maximum column value is susceptible to data loss when extracting from transactional systems such as SAP. There is no guarantee that between 2 rows, the row committed last has the higher timestamp, leaving the door open to data loss depending on the timing of delta loads.
This finding applies not only to row timestamps, but also to auto-increment numbers such as change numbers. You can follow the same chain of events with emphasis on the column ID to track this.
The solution was to instead delta load our change log table by storing a “snapshot” of to-be-extracted-rows before the extraction begins. We did this by using a UUID “reference” column in the change log table:
When the extraction starts, create a UUID and set the "Reference" column for each row in the change log table to this UUID
During extraction use the filter “reference = UUID”
After extraction delete from the change log using the same filter
This approach also has its own pitfalls, but that’s probably a topic for another blog post.
This article is a joint effort of Simon Brydon and Svenja Matthaei

More blog posts on Celonis Engineering Blog
